
Обоснование решений. Использование метрик при выборе технологий
Проблема
На одном из текущих проектов встала необходимость выбрать поисковой движок. Система разрабатывается на основе одного из PHP-фреймворков, приближающего удобство работы к Ruby on Rails. База данных — PostgreSQL. Пользователи чаще всего ищут документы среди здоровенной базы текстовых материалов, лежащих в файловой системе. Но могут и уточнить запрос через расширенный поиск — тут нужно использовать еще и атрибуты документа, которые хранятся в базе данных.
Весь контент на русском языке, так что простым сравнением запроса с текстом документа не обойтись — нужно учитывать морфологию. Да и объем хранилища немаленький, с перспективами многократного роста, так что нужны хорошие механизмы индексации. Такие движки есть у двух популярных поисковиков — Яндекса (Яндекс.Сервер) и Google (Google Search Appliance). Причем у первого есть бесплатная версия, пусть и с ограничениями. На первом этапе проекта клиент больше занят созданием и отладкой общей инфраструктуры компании, так что готов по максимуму использовать бесплатное ПО. Поэтому даже чужой логотип в результатах поиска вполне терпим, да и заказчик всеми руками за известный бренд.
Тут всплывает первая проблема. Яндекс.Сервер позволяет искать по полям БД только в платной версии. Значит нужно совмещать два результата поиска — полученный внешним движком и собственный, по полям базы данных. Либо искать компромиссное решение. Первый вариант имеет тонну технических подводных камней. Даже найдя после брейншторминга более-менее подходящую схему взаимодействия двух движков, нерешенными остаются и производительность, и релевантность итоговых результатов, и еще серия моментов. Нужно ведь чтобы сперва отработал один из поисковиков, затем передал результаты другому, чтобы искать уже только среди них. А кроме этого — задача обработать, склеить, отсортировать итоговый список.
С компромиссными вариантами также обнаружились проблемы. Альтернативные поисковые механизмы есть в достаточном количестве. Но окончательно убедить клиента в том, что они смогут получить хоть как-нибудь сравнимое с Яндексом качество поиска в русскоязычных текстах никак не получалось. Так что вопрос долго футболился между обсуждениями итогового решения и необходимостью дополнительных исследований.
Решение
Чтобы закончить неопределенность и объяснения на пальцах, мы решили подойти к вопросу формализованным способом. Для этого определились с набором характеристик поисковика, которые важны в разрабатываемом продукте:
- производительность:
- скорость работы;
- выдерживаемые нагрузки;
- качество:
- поиск по базе данныхo;
- поиск по файловой системе;
- релевантность;
- морфология;
- стоимость;
- совместимость с ПО;
- перспективность:
- бренд и перспективы развития;
- наличие крупных и известных проектов, использующих движок;
- опытность и размер команды разработчиков движка.
Все это нужно для выбора из следующего списка:
Список неоднороден — тут и отдельный поисковой сервер, и просто подключаемые библиотеки. Но наша задача — выдавать удовлетворяющий требованиям результат. А точный формат взаимодействия основной системы и поисковика в них не задан. Так что тут у нас полная свобода действий.
Теперь можно проводить более детальный анализ. Для каждого из поисковых механизмов указано, насколько он соответствует требованиям. Совместимость с ПО обязательна для всех, так что ее можно вынести за скобки. Там же остались и некоторые другие параметры — например, технологическая сложность интеграции двух движков. Главное не переборщить — на исследование по сотне пунктов уйдет тонна времени, хотя может быть вполне достаточно и десяти.

В итоге был выбран движок Sphinx. Он не так известен как Яндекс, но имеет очень хорошие показатели по всем важным нам параметрам. Да и по самой тревожившей клиента характеристике — морфологии — различие не настолько критичное. К тому же, проект делает российский разработчик.
Развитие решения
Простое сопоставление вариантов решений с характеристиками помогло сделать более быстрый выбор с минимальными усилиями. В более сложных случаях подход к выбору можно сделать еще более формализованным — трудно сравнивать “хорошо” и “$90 тыс”. Для этого проставим каждому из движков балл по каждой из характеристик. Можно взять банальное от 1 до 5 и расставить оценки на глазок. Можно для каждой метрики выбрать суб-характеристики и уже на их основе определить балл. Тут все зависит от того, насколько важно исследование. Для моего случая табличка будет такой:

Что делать, когда количественные значения метрик получены? Можно опять же сделать выбор на глаз. А можно получить итоговый балл, решение с наибольшим значением по которому и будет искомым. Правда, простая сумма будет не очень адекватной и лучше каждой характеристике определить вес, на который она будет множиться при сумме:
Балл = P1*A1 + P2*A2 + … + Pn*An
где Pn — вес метрики, An — балл по метрике
Характеристик у нас 10, суммарный балл по ним — 33. Выходит, вес одного балла — 3,03% (т.е. 100% / 33). Получим такую табличку весов:
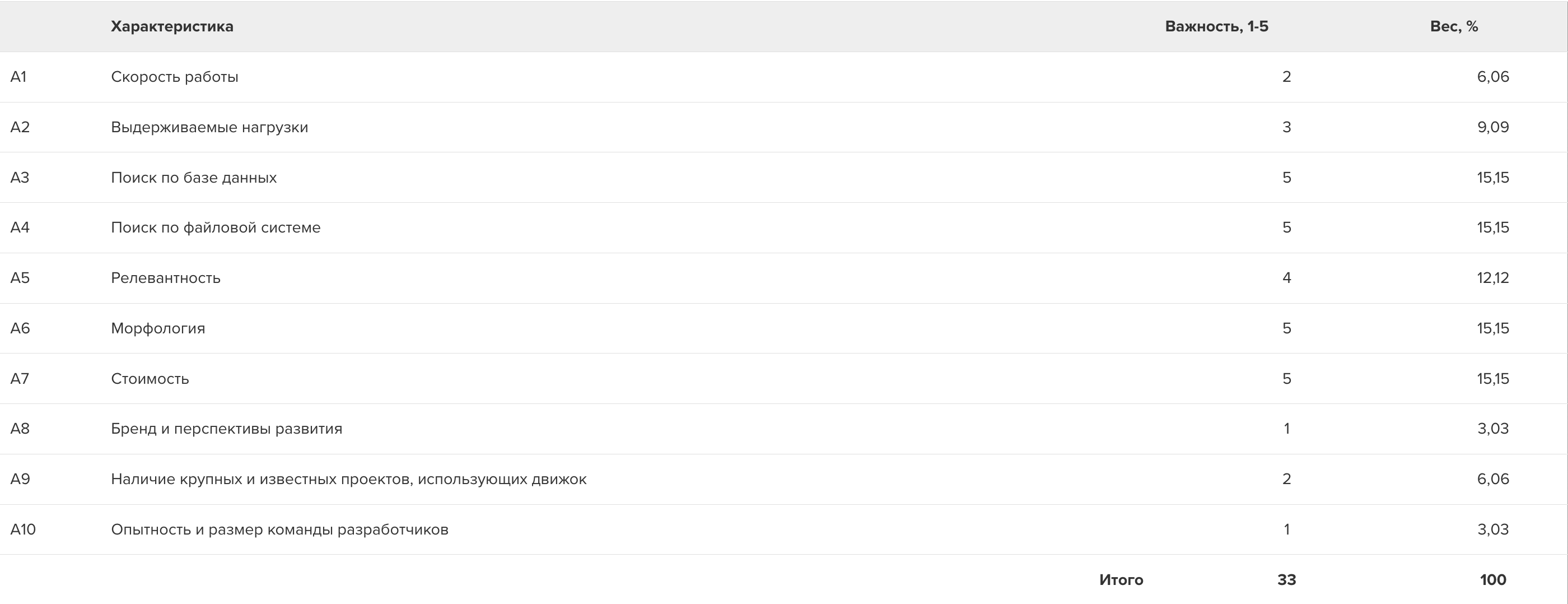
В итоговом расчете получаем вот что:

Первое место и тут оказалось за Sphinx. В принципе, мы поняли это уже при первом сопоставлении. Но с точными данными на руках гораздо проще доказать правильность этого выбора. Иначе его очевидность будет понятна не всем и придется еще долго и упорно ее доказывать.
Аналогичные методики работают и в других случаях. Например, “расчет телодвижений” GOMS при сравнении эффективности интерфейсных решений. Или просто подсчет рейтингов для чартов на основе серии факторов. На такие количественные расчеты может уйти уйма времени — не всегда рационально их использовать. Но иногда сделать правильный выбор вслепую гораздо сложнее. Да и доказать его обоснованность на пальцах не проще.
P.S. Сейчас мы как раз выбираем новую технологию разработки для крупных веб-проектов. Так что, возможно, скоро появится и вторая часть материала по мотивам этого исследования.

